
Visual Indexing
The Key to Multiple Paradoxes in the Cognitive Sciences


"What is that? I've never seen that thing before!" is something Artificial Intelligence (AI) programs are incapable of saying. That is because convolutional neural networks only “see” objects that their developers have programmed them to recognize. They remain blissfully unaware of everything else. This is backward from how humans perceive things and is the subject of this note. Our ability to recognize things as Objects1, even when we don't know what kind of object they are, is what allows us to learn new things on our own.
Convolutional Neural Networks, like YOLO2, are adept that recognizing a lot of different objects: people, cars, bicycles, traffic lights, and so on. It works by first recognizing objects and then drawing a box around those recognized objects. This neural network only recognizes objects that programmers have trained it to recognize. In the image shown below, YOLO does not see a street sign, cross-walk, utility hole cover, street light, or building because nobody has trained YOLO to recognize them.

You Only Look Once (YOLO) is a popular convolutional neural network that recognizes objects.3
Humans (and presumably other animals) do the opposite: we rapidly detect and track up to five (give or take) Objects—unconsciously—and only then do we determine what those objects are. Unrecognized objects stimulate our curiosity (an innate emotion)4. We might ask, "What's that thing?", and inspect it closer. We might give it a temporary name like thingamabob. Object detection and tracking in humans is fast and pre-attentive: it is a feed-forward only process that we remain unaware of. We know this because of the psychological Multiple Object Tracking (MOT) research of Zenon Pylyshyn. I know that Pylyshyn's theory is computationally feasible because of my computational vision work.
Fingers of Instantiation
Zenon Walter Pylyshyn was a Canadian cognitive scientist that studied the human cognitive systems behind perception, imagination, and reasoning. He died December 2022 in New York City. Without getting into the weeds of his research, he proposed something so incredible, counter-intuitive, and controversial that computer scientists and image processing people don't know what to make of it:
Our visual system tracks objects (up to five) pre-attentively and without recognition. Each visual track is an indirect reference or index to a projected object according to its location only without consideration of object features, such as color, shape, texture, or edges. After our visual system indexes an object, our brain seeks to recognize it using object features. Only then, recognized or not, does the object enters our consciousness.
This theory flies in the face of the more mainstream view that object detection is based on the object’s visual feature set.
Pylyshyn called these visual indices FINSTs or Fingers of INSTantiation. They resemble pointers to things rather than a collection of spatial features. His theory is called FINST Theory or Visual Indexing Theory.5
A mainstream theory of visual perception, the spotlight or zoom-lens theory of attention, asserts that "Attention can be likened to a spotlight that enhances the efficiency of detection of events within its beam"6. This describes a top-down, singular process. FINST differs from focus of attention in several ways:7
There can be multiple indexed Objects at any moment
The process is data-driven or bottom-up, not top down
Indices correspond to an Object's outline or projected profile, neither a location nor a vague region
Indices track the Object as it moves around, and
The visual properties of the Object do not mediate the indices being tracked
Wearing my image processing hat, I immediately recognized several benefits of pre-attentively recognizing Objects independent of their features:
Pre-attentive and feed-forward means the process is likely to be faster than a recursive or top-down process.
Recognizing Objects independently of their visual features allows a system to learn about objects never encountered before. By contrast, YOLO cannot detect or see anything it has not been trained to recognize.
Unlike most convolutional neural networks like YOLO, FINSTs define the object's outline, not simply a bounding box. This allows one to inspect or learn the features of an object more precisely without the irrelevant visual noise of surrounding backgrounds.
Visual Indexing provides insights to at least five paradoxes in the cognitive sciences:
Visual indexing provides a mechanism for Egomotion Invariance. We perceive stationary things as stationary, even when we are moving. By tracking objects pre-attentively, we remain unaware of image motion on the retina induced from our own eye movement (saccades) and body movement (egomotion).
Tracking an object partially obscured by a pole or a fence is challenging for computers because the pole or fence visually chops the tracked object into two or more disjoint regions. Humans have no problem seeing a set of disjoint pieces (see below) as a grouped entities. We do this effortlessly and pre-attentively. This is one example of a phenomenon called Gestalt Grouping. Visual indexing allows us to track multiple disjoint pieces. The pieces (Objects) that share similar visual features and motion dynamics can be grouped/perceived as one object.

Two horses visually chopped into six pieces. Obvious to you and me. Less obvious to AI.
The Binding Problem asks how features, such as an apple's visual attributes of redness and roundness, combine into a single experience. How does redness and roundness somehow become attached (bound) to an object's set of attributes? This is a tricky question because we are not talking about a computer in which we can simply assign a value of RED to an object's COLOR attribute. There are no innate symbols or data type conventions (e, g., ASCII, floating point, bitmap, WAV) in the human brain as there are in computers. There are just neurons that get activated or not. A visual index potentially provides a nexus for the simultaneous activation of visual feature neurons, such as RED and ROUND.
Related to the binding problem is the question of representation in the brain. A representation is a thing that stands for another thing, but is not the same as the thing it represents. The image of the metal spinning top above is a representation. But if you saw it for the first time in the palm of your hand, the perception of it is not a representation. But once you call it a thingamajig or a spinning top, you will have created an internal representation. Indices are temporary references to things without being representations8.
Subitizing9 is how most animals count and it is how you and I count the dots on dice: we recognize a count immediately without sequentially counting dots. Subitizing in humans works for small numbers, typically 1-6. Honey bees can count to four!10 In order to recognize a count of items, we need to first group or perceive those items as a single Object. Visual Indexing provides a way to do that.

This all sounds promising. But how does it work? Pylyshyn did not provide many suggestions that I am aware of. He described the phenomena of visual indexing in human test subjects, but he did not propose a mechanism for how it worked. I conducted online searches to no avail.11 I contacted several of Pylyshyn's colleges seeking computational models of FINSTs but found none. So I set out to create my own computational model of visual indexing.
Go With The Flow
If you ignore all characteristic visual features like shape, color, contrast (lines), and texture, what remains of an opaque object? The answer is this: the object can obscure other, more distant objects, and an object can be obscurred. In addition, an object has a spatial relationship with the observer and other objects around it: closer objects appear to move faster or loom larger as the observer moves forward. Recall looking out the window of a fast-moving train: close objects stream by faster than more distant ones. Movement of the object and/or the observer reveals different types of edges and spatial relationships. Allow me to give you an example.
The image below contains two layers. Its background layer is random Perlin noise12. The foreground layer is transparent except for a circle also filled with Perlin noise. The circle is virtually invisible against the background because it shares the same Perlin noise parameters as the background.

A static image of disk against a background. Perlin noise fills each. Illustration by author.
Now if I move the disk—shown in the GIF animation below—we immediately see it and recognize the outline of a disk. We recognize the outline of some kind of Object. Your detection of the Object is not based on internal visual features. Shape (a circular disk) is a visual feature but—as illustrated in the static image above—it alone cannot account for your detection of it.
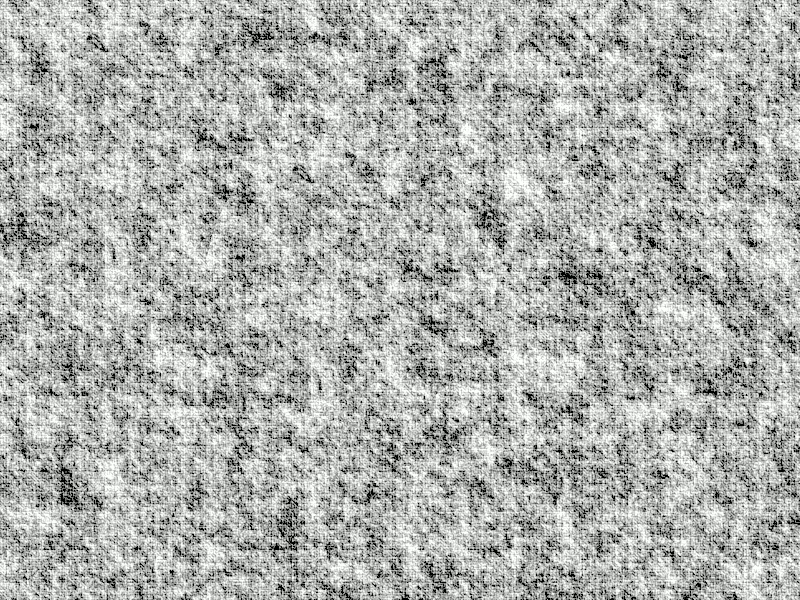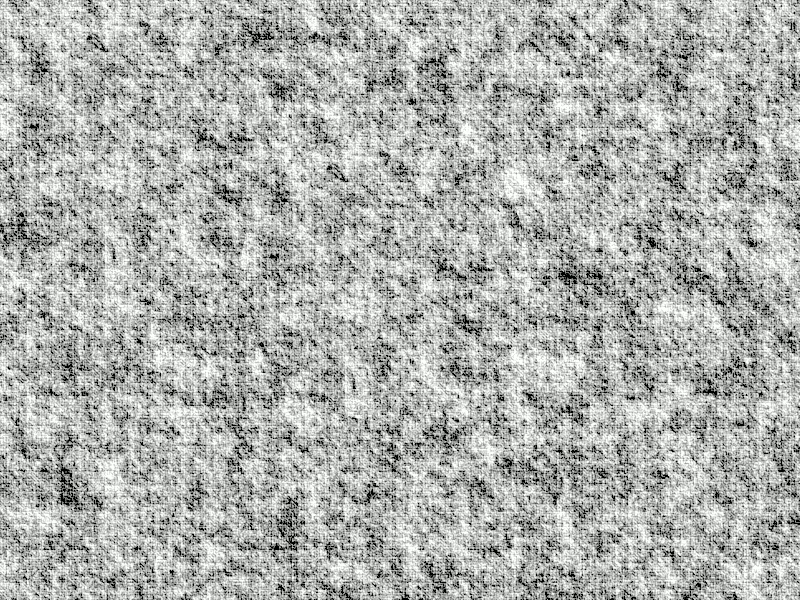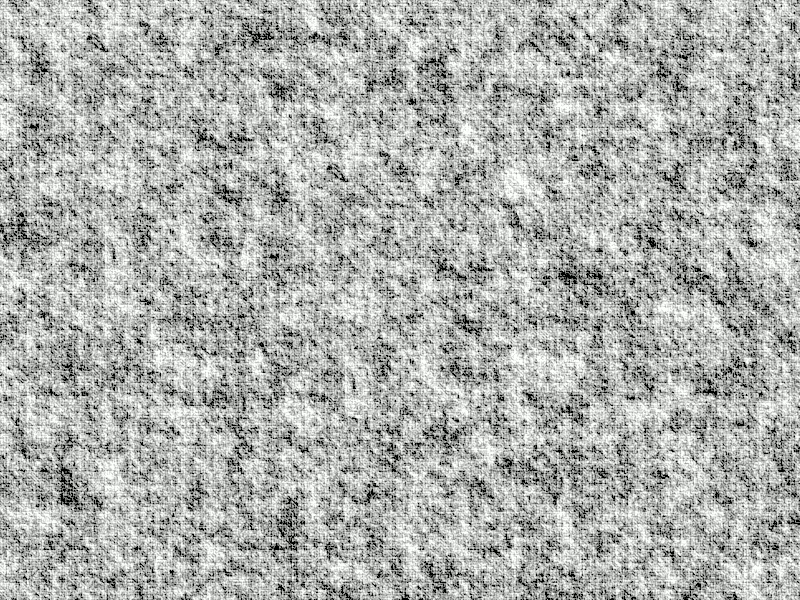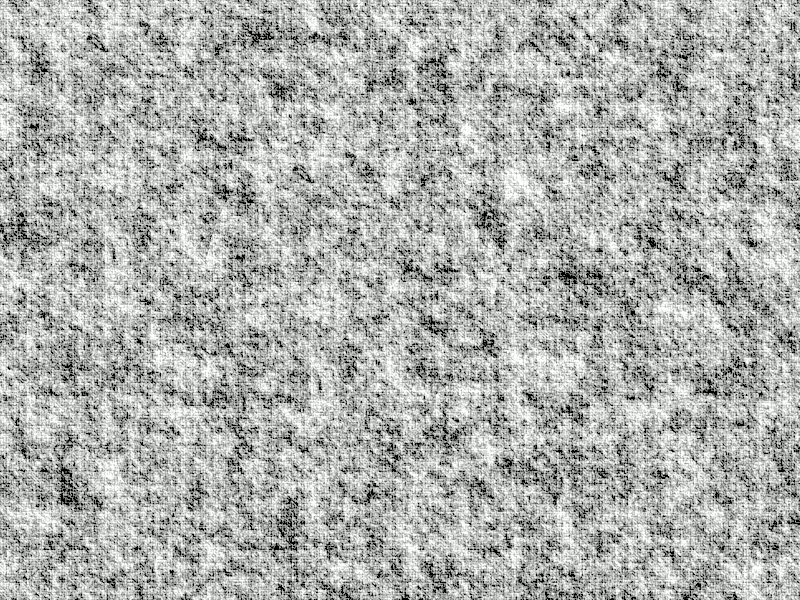
A GIF animation of the same disk as above but now moved against the same background. If you do not see an animation, view the image in a Substack web page. Animation by author.
How can we explain these phenomena? The illustration below shows what happens when one disk moves to the right. The leftmost edge reveals a crescent-shaped region that was previously obscured. I've colored this region in red. However, the rightmost edge now advances and covers a region previously visible. I have colored it green.
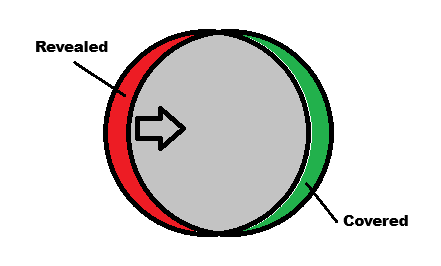
Illustration of a disk moving to the right showing regions previously obscured (red) regions and regions newly obscured (green). Illustration by author.
What the illustration above does not show are the spaces to the left of the revealed space and to the right of the covered space: they neither change nor move. However, the entire gray space and the covered green space moves. We can combine these facts to determine which edges are advancing and which edges are retreating. Using rate of movement and other spatial constraints, we can pair advancing and retreating edges to infer the boundaries of Objects.
I propose that the mammalian vision system includes detectors (similar to Reichardt's motion detector but a little more complex) that detects not only motion but identifies edges as advancing or receding and, ultimately, the objects they surround.
I am currently developing algorithms that infer advancing and receding edges and the objects that they bound. My goal is to deploy a computational solution in real time on a $50 credit-card-size computer.13
One way to reduce computational complexity, execution time, and power demands is to limit the generality of the solution. Evolution does this all the time. You and I can recognize faces much easier when they are right-side up than when they are upside down. Evolution made a bet that not recognizing faces equally in all orientations was worth the savings in complexity and energy. I think it was a good bet. My bet is that I can get by initially only tracking vertical edges.
My goal is for a tiny drone to fly through a forest of trees using only a passive, monocular vision sensor. Honey bees can do this, so I know it is possible. The obstacles I worry most about are trees. Trees generate a lot of vertical lines. By focusing on vertical lines, I can quickly reduce the amount of data to be processed. It also means that I can avoid computationally expensive optic flow algorithms.
I will post progress on this project later this year (with video). This is the first part of a larger effort to create a pre-attentive (feed-forward) spatial awareness system. It will be a computationally simpler and more biologically feasible approach to Simultaneous Localization And Mapping or SLAM. Stay tuned.
In this post, I distinguish between objects in the world (person, truck, tree, duck) and Objects (capitalized) that we perceive but may or may not recognize (e.g., the metalic Object shown at the beginning of the post).
Redmon, J., Divvala, S., Girshick, R., & Farhadi, A. (2016). You only look once: Unified, real-time object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 779-788).
Image from Yolo Object Detection Made Easy.
Redmon, J., Divvala, S., Girshick, R., & Farhadi, A. (2016). You only look once: Unified, real-time object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 779-788).
Ahmadlou, Mehran, Janou H. W. Houba, Jacqueline F. M. van Vierbergen, Maria Giannouli, Geoffrey Alexander Gimenez, Christiaan van Weeghel, Maryam Darbanfouladi, et al. “A Cell Type–Specific Cortico Subcortical Brain Circuit for Investigatory and Novelty-Seeking Behavior.” Science 372, no. 6543 (May 14, 2021). https://doi.org/10.1126/science.abe9681.
Visual indexing theory – Wikipedia. See also Pylyshyn, Zenon W. (2007). Things and Places: How the Mind Connects with the World. MIT Press.
Posner, M. I., Snyder, C. R. R. and Davidson, B. J. (1980). Attention and the Detection of Signals. Journal of Experimental Psychology: General, Vol. 109, No. 2, 160-174.
Dedrick, Don & Trick, Lana (eds.) (2009). Computation, Cognition, and Pylyshyn. MIT Press.
I know I am walking on thin philosophical ice here asserting that an index is not a representation. My goal is not to get into a pissing contest on what counts as a representation. My goal is to build a system capable of constructing its own representations independent of genetically-encoded declarative knowledge or symbols, representational data typing, or other influences from external intelligent agents.
Chittka L, Geiger K. 1995. Can honey-bees count landmarks. Anim. Behav. 49, 159–164. 10.1016/0003-3472(95)80163-4)
Do you know of any computer models of Visual Indexing? If so, please let me know.
There is quite a large collection of image processing papers on using optic flow to detected obscuring edges. I will include some of them in an update.
I thought bees have five eyes though?
“This all sounds promising. But how does it work? Pylyshyn did not provide many suggestions that I am aware of. He described the phenomena of visual indexing in human test subjects, but he did not propose a mechanism for how it worked.”
Sounds like an ambitious project Tom! But it also leaves me scratching my head about how it could be consistent with your last post that the brain/computer analogy is a bad one. Aren’t you using a simple computer that drives a drone by means of indexing, to demonstrate mechanisms by which the human might visually index what’s “seen”? Thus in that sense at least shouldn’t the brain be considered “computational”?
I happen to like the brain/computer analogy because I think the brain accepts incoming nervous system information, processes it algorithmically, and then the processed information goes on to operate various output mechanisms. To me that seems like a good definition for “computer”. The brain should quite directly operate heart muscles this way for example.
(One implication is that there must be something which this computer operates that exists as consciousness. I suspect certain parameters of electromagnetic field serve this role. Essentially the right sort of synchronous neuron firing gets into a physics mandated zone such that the produced field itself resides as all that we see, think, and so on. Then the thinker’s decisions (which of course reside under the unified field) hit energies that alter neuron firing to cause muscle function in ways that correspond with what was decided.)
Though I’d love for you to assess my EMF consciousness position some day, I don’t mean to make this about me. If I’ve misinterpreted this post regarding human indexing, or the last one about how the brain/computer analogy is a bad one, then I figure I should give you the opportunity to straighten me out.